من الإنجليزية البسيطة إلى الرؤية: كيف يعيد الذكاء الاصطناعي تشكيل تصور البيانات

من الإنجليزية البسيطة إلى الرؤية: كيف يعيد الذكاء الاصطناعي تشكيل تصور البيانات
معظم بيانات الأعمال لا يُنظر إليها أبداً. فهي تقبع في قواعد البيانات والمستودعات وجداول البيانات، تنتظر شخصاً يمتلك مهارة الاستعلام المناسبة واللوحة المناسبة لإظهارها. لسنوات، ظلت الفجوة بين امتلاك البيانات وفهمها واحدة من أهدأ المشكلات وأكثرها كلفة في عالم الأعمال. والآن يعمل تصور البيانات المدعوم بالذكاء الاصطناعي على سدّ تلك الفجوة — محوّلاً سؤالاً مكتوباً إلى رسم بياني في ثوانٍ.
تشرح هذه المقالة كيف يعمل ذكاء البيانات باللغة الطبيعية فعلياً، وأين يقدّم قيمته، وما الذي ينبغي الانتباه إليه قبل أن تأتمنه على قراراتك. سنُرسّخ التقنية على أساس متين أولاً، ثم نوضّح كيف يندرج نهج Apivom Pivot ضمن ذلك.
عنق الزجاجة الحقيقي لم يكن البيانات يوماً
لا تعاني المؤسسات من نقص في البيانات. وفقاً لمسوحات القطاع، يتضاعف حجم بيانات المؤسسات تقريباً كل عامين، ومع ذلك تُفيد معظم الفرق بأنها تستخدم جزءاً ضئيلاً منها فقط في القرارات. القيد نادراً ما يكون التخزين أو الجمع — بل هو الترجمة.
للإجابة عن سؤال بسيط مثل «أي المناطق تراجعت في التجديدات الربع الماضي؟»، يحتاج المدير غير التقني تقليدياً إلى ثلاثة أشياء:
- شخص يعرف نموذج البيانات ويستطيع كتابة SQL أو استعلام ذكاء أعمال.
- لوحة تحتوي مسبقاً على ذلك المقطع المحدد من البيانات.
- وقت — عادةً يوم أو أكثر في طابور الطلبات.
عندما يغيب أيٌّ من هذه، يبقى السؤال دون إجابة أو يُستبدل بحدسٍ شخصي. اضرب ذلك في مئات القرارات الصغيرة أسبوعياً، فتصبح كلفة فجوة الترجمة هائلة. هذه هي الفجوة التي تستهدفها تحليلات اللغة الطبيعية مباشرةً.
كيف يعمل ذكاء البيانات باللغة الطبيعية
تبدو عبارة «اسأل بياناتك سؤالاً» وكأنها تسويق، لكن تحتها مسار ملموس متعدد المراحل. فهم المراحل يساعدك على الحكم على أين تكون هذه الأنظمة موثوقة وأين لا.
المرحلة 1: فهم القصد
يحلّل النظام السؤال أولاً ليحدّد ما الذي يُطلب — المقياس (التجديدات)، والبُعد (المنطقة)، والمرشّح (الربع الماضي)، والمقارنة المرغوبة. تستخدم الأنظمة الحديثة نموذجاً لغوياً كبيراً هنا، لكن الجيدة منها تقيّده بشدة بسياق المخطط حتى لا يختلق أعمدة غير موجودة.
المرحلة 2: توليد الاستعلام
بعد ذلك، يُترجَم القصد إلى استعلام فعلي على قاعدة البيانات — عادةً SQL. هذه هي الخطوة التي كانت تتطلب تاريخياً محللاً بشرياً. يرسّخ النظام المُحكَم النموذج في أسماء الجداول والأعمدة الحقيقية والعلاقات وأنواع البيانات، بحيث يكون الاستعلام المُولَّد صالحاً وآمناً للتشغيل.
المرحلة 3: اختيار التصور
نتائج الاستعلام الخام مجرد صفوف. الاتجاه عبر الزمن يتطلب رسماً خطياً؛ وتفصيل الجزء من الكل يتطلب رسماً شريطياً أو دائرياً؛ والمقطع الجغرافي يتطلب خريطة. تختار الأنظمة الناضجة نوع الرسم من شكل النتيجة لا من تخمين، فيكون المُخرَج قابلاً للقراءة دون تنسيق يدوي.
المرحلة 4: شرح النتيجة
المرحلة الأخيرة، والمُهمَلة غالباً، هي السرد: ملخص قصير بلغة بسيطة لما يُظهره الرسم — القيمة الشاذة، والاتجاه، وتقسيم 80/20. هذا ما يحوّل التصور إلى رؤية فعلية يستطيع مديرٌ مشغول التصرف بناءً عليها.
أين يقدّم القيمة — وأين لا
تحليلات اللغة الطبيعية ليست سحراً، والتعامل معها على هذا النحو أسرع طريق لفقدان الثقة بها. فهي تتألق في مواقف محددة وتتعثر في أخرى.
تعمل جيداً في:
- الأسئلة الاستكشافية — «أظهر لي مخاطر التسرب حسب خط المنتج» — حيث تكون السرعة أهم من الدقة الكاملة.
- الخدمة الذاتية لغير المحللين — تمكين مسؤول مبيعات أو مدير مالي من الإجابة عن أسئلته دون تذكرة طلب.
- الاكتشاف الأولي — إظهار الحالات الشاذة والاتجاهات والشرائح الجديرة بنظرة أعمق.
تتعثر في:
- مصطلحات الأعمال الغامضة — إن كان «العميل النشط» يعني ثلاثة أشياء مختلفة بين الأقسام، فالنظام يحتاج طبقة مقاييس مُعرَّفة لا تخميناً.
- التقارير الخاضعة لحوكمة صارمة — لا تزال الأرقام التنظيمية أو المالية تتطلب استعلامات مُدقَّقة وخاضعة لضبط الإصدارات.
- المنطق المتداخل العميق — لا تزال الحسابات متعددة الخطوات ذات الحالات الحدّية تستفيد من مراجعة محلل بشري.
الخلاصة العملية: استخدم تصور الذكاء الاصطناعي لتسريع الطريق إلى إجابة السؤال، وأبقِ الإنسان في الحلقة حيثما قادت الإجابة قراراً خاضعاً للتنظيم أو عالي المخاطر.
الضوابط الوقائية أهم من النماذج
أكبر فارق بين عرض تجريبي لعبة ونظام بمستوى الإنتاج هو الضوابط الوقائية. النموذج الذي يستطيع كتابة أي SQL يستطيع أيضاً كتابة استعلام بطيء أو مكلف أو غير آمن. تُحيط أنظمة الإنتاج خطوة التوليد بحمايات:

- وصول للقراءة فقط بحيث لا يمكن لسؤال أن يعدّل البيانات أبداً.
- ترسيخ المخطط بحيث يشير النموذج إلى الجداول الحقيقية المسموح بها فقط.
- عزل المستأجرين بحيث لا يمسّ سؤال عميل بيانات عميل آخر أبداً.
- التحقق من الاستعلام ووضع الحدود بحيث لا يُثقِل استعلام جامح قاعدة البيانات.
إن كنت تقيّم أي أداة تحليلات باللغة الطبيعية، فينبغي أن تكون هذه الضوابط أول ما تسأل عنه — قبل جماليات الرسوم بوقت طويل. وغالباً ما تكون طبقة بوابة API القوية هي المكان الذي تُطبَّق فيه هذه الحمايات باتساق عبر الخدمات.
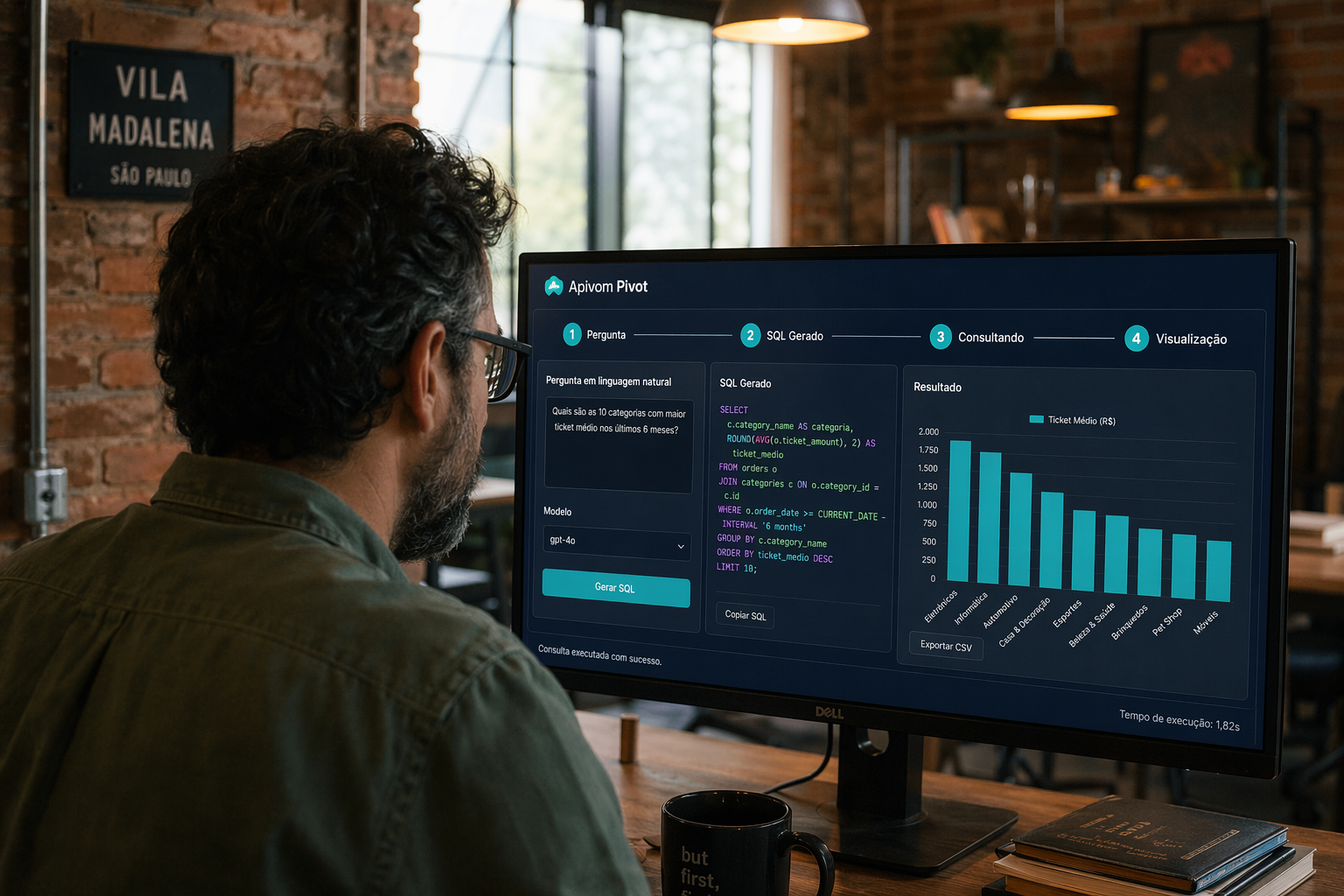
نهج Apivom Pivot
هنا يسدّ Apivom Pivot الفجوة. بُني Pivot كطبقة ذكاء بيانات باللغة الطبيعية تتبع تماماً المسار رباعي المراحل أعلاه — القصد، والاستعلام، والتصور، والشرح — لكنه يُحيط كل مرحلة بضوابط إنتاجية افتراضياً.
يُوجَّه السؤال المكتوب بلغة بسيطة عبر مسار متعدد الوكلاء: مرحلة تفسّر القصد، وأخرى ترسّخ وتولّد SQL على المخطط الحقيقي، وثالثة تختار تصور ECharts المناسب من شكل النتيجة، ومرحلة أخيرة تكتب ملخصاً سردياً قصيراً. يعمل كل استعلام بصلاحية القراءة فقط ومع عزل المستأجرين، فيكون السؤال نفسه آمناً سواء جاء من مدير مبيعات أو من مسؤول مالي.
ولأن Pivot يتصل بالبيانات التشغيلية الحية عبر البوابة نفسها التي تُشغّل بقية المنصة — بما في ذلك Apivom Iris لبيانات العملاء والإيرادات — تعكس الإجابات الحالة الراهنة للأعمال لا تصديراً ليلياً قديماً. والنتيجة أن من لا يملك مهارات SQL يستطيع أن يسأل «أي الحسابات الأكثر عرضة للتسرب هذا الربع؟» ويحصل على رسم بياني مُرتَّب مع شرح من فقرة واحدة، في ثوانٍ.

ماذا يعني هذا عملياً
الانتقال من بناء اللوحات إلى طرح الأسئلة يغيّر مَن يستطيع استخدام البيانات. فعندما يستطيع مدير الإجابة عن سؤال متابعة في عشر ثوانٍ بدلاً من تقديم طلب والانتظار يوماً، يتسارع إيقاع صنع القرار بأكمله.
النتائج القابلة للقياس ملموسة: يتحرّر وقت المحلل من طلبات الاستعلام الطارئة ويُوجَّه نحو عمل أعمق، وينخفض الزمن من السؤال إلى الإجابة من أيام إلى ثوانٍ، وتبدأ القرارات التي كانت تعتمد على الحدس بالاعتماد على الأرقام الفعلية. لا يحل التصور المدعوم بالذكاء الاصطناعي محل المحللين — بل يزيل الطابور أمامهم ويمنح الجميع طريقاً أسرع إلى البيانات التي يملكونها أصلاً.